
Context Engineering: Improving AI Coding agents using DSPy GEPA
Context Engineering applied on coding agents (autoanalyst.ai)

This blog post is a technical walkthrough of how you can improve an AI coding agents used in the AI data scientist, using DSPy prompt optimization using GEPA.
The blog covers the following topics:
Preparing data
Explaining GEPA
Applying prompt optimization (GEPA) via DSPy
Results

1. Preparing Data
The dataset is made up of Python code execution runs done through our product. The auto-analyst is an AI system with multiple parts, each designed for a specific coding job. One part, the pre-processing agent, cleans and prepares the data using pandas. Another part, the data visualization agent, creates charts and graphs using plotly.
The system has about 12 unique signatures, each with two versions — one that uses the planner, and one that runs on its own for ‘@agent’ queries.
But for this blog post, we’ll focus on just 4 of those signatures and their two variants. These 4 alone make up around 90% of all code runs, since they’re the default ones used by almost everyone, whether they’re free or paid users.
preprocessing_agent
data_viz_agent
statistical_analytics_agent
sk_learn_agent
We can break the dataset down into two parts: the default dataset provided by the system and the data that users upload themselves.
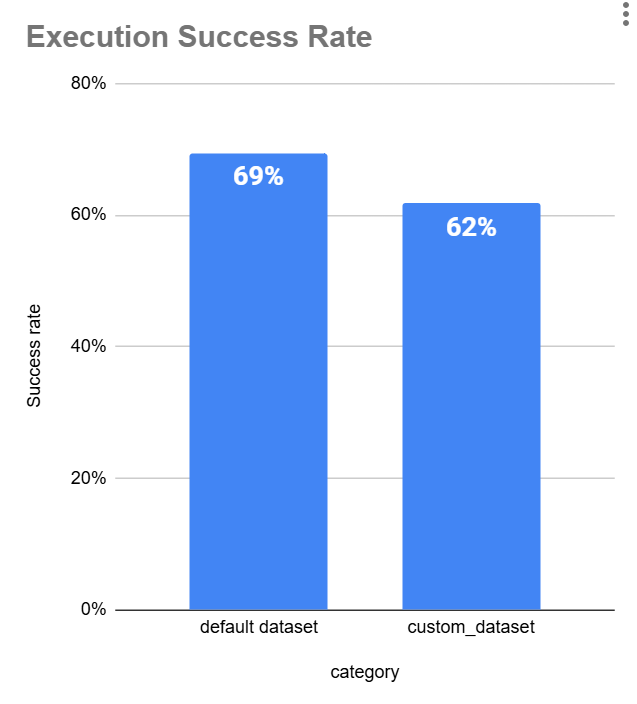
Our goal is to make sure any optimization improves performance on both. It should work well not just on the default data but also on the datasets users upload.
To do this, we need to stratify the data. That way, the model doesn’t overfit on the default dataset and can handle a variety of inputs effectively.
Another important factor we need to consider is the model providers. We don’t want to optimize just for one provider and end up hurting performance on the others.
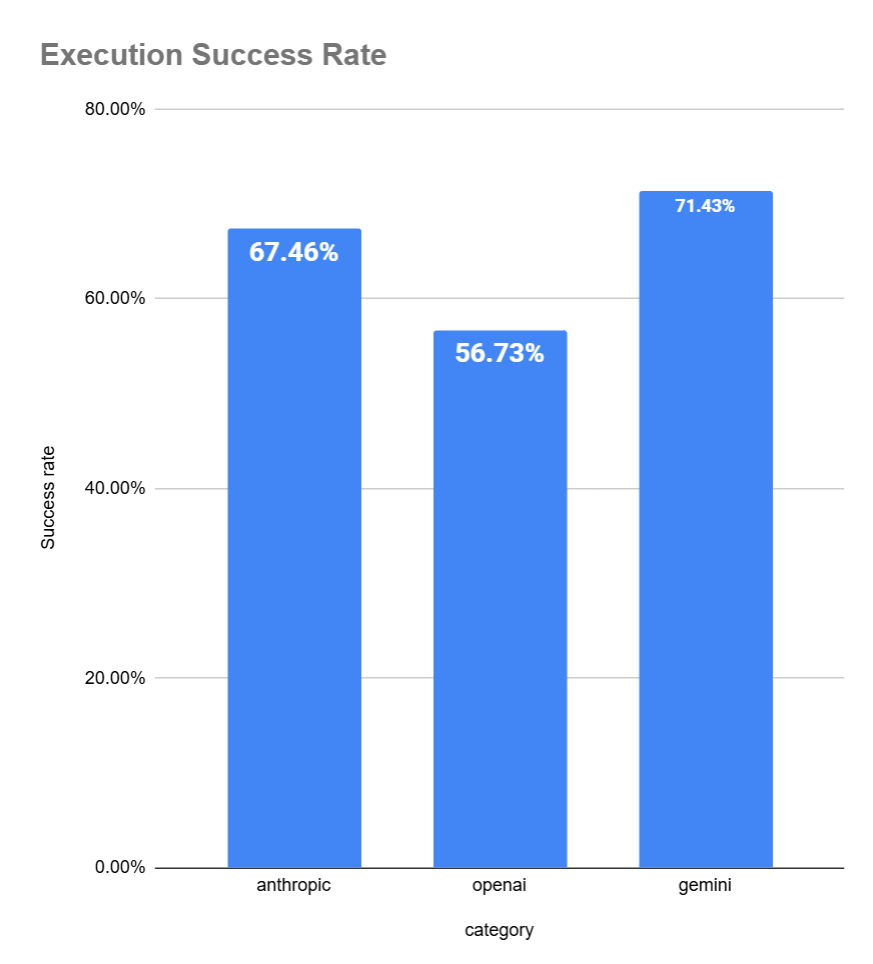
Note: There’s bias in this because our users mostly used OpenAI’s cheaper models like GPT-4o-mini in our system, while for Gemini, our users used only their top models. Since we don’t have enough data to evaluate on a per-model basis, we’re using the provider as a proxy. When comparing top OAI models with the top models of other providers, OpenAI’s success rate is similar.
After preparing the dataset, we created a stratified sample with the following constraints:
No more than 20% of the data comes from the default dataset (
is_default_dataset == True).Each of the three model providers (
openai,anthropic,gemini) is represented in at least 10% of the final sample.Stratification was done across three columns:
model_provideris_successfulis_default_dataset
Once the stratified sample was created, we split it into a training set and a test set to be used for evaluation.
2. Explaining GEPA
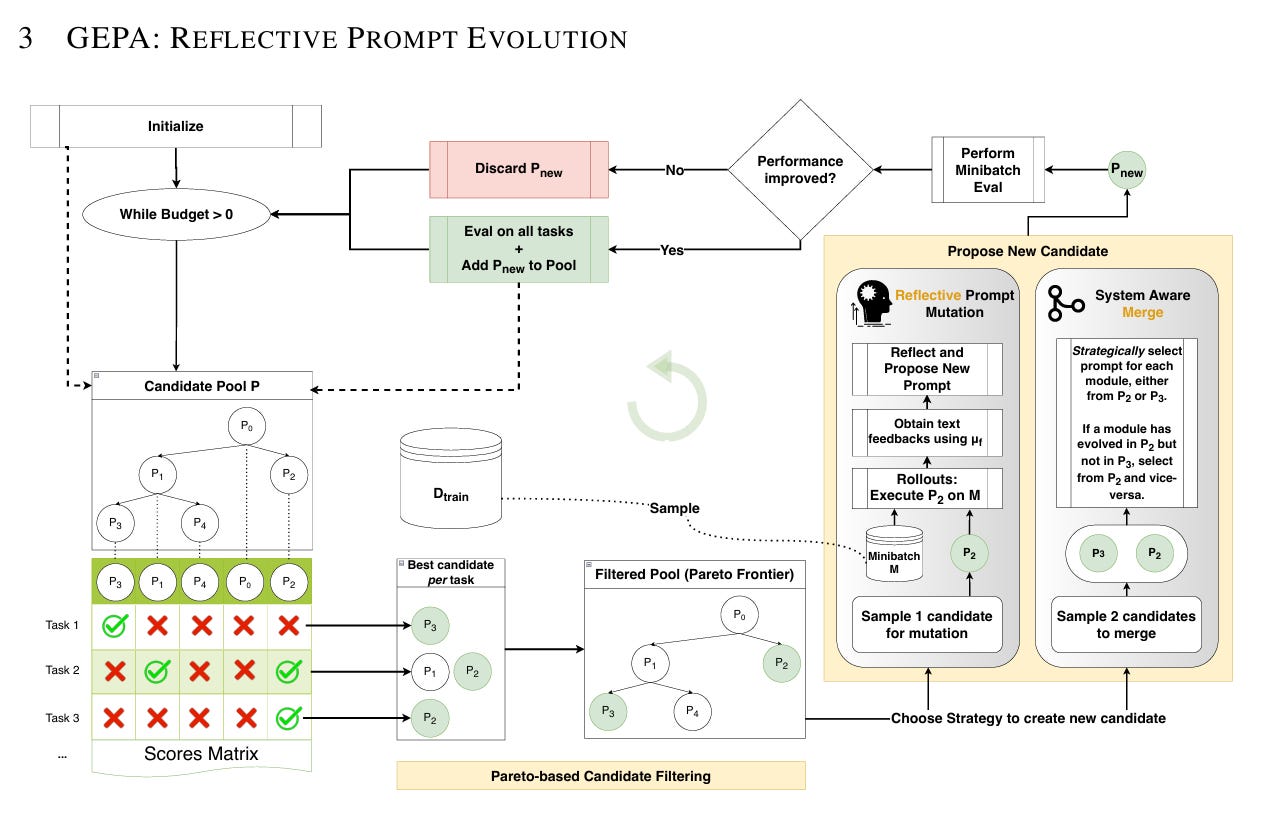
GEPA stands for (Generic-Pareto), an evolutionary prompt optimizer designed for DSPy programs that uses reflection to evolve and improve text components such as AI prompts.
GEPA leverages large language models’ (LLMs) ability to reflect on the program’s execution trajectory, diagnosing what worked, what didn’t, and proposing improvements through natural language reflection.
It builds a tree of evolved prompt candidates by iteratively testing and selecting better prompts based on multi-objective (Pareto) optimization.
Step-by-step, here is what GEPA does as an evolutionary prompt optimizer in DSPy:

 | A guest post by
|