
Do AGENTS.md/CLAUDE.md Files Help Coding Agents? A New Paper Challenges this

Over the past year, adding an AGENTS.md or CLAUDE.md file to your coding repository has quietly become standard practice when using the coding agent. Agent vendors recommend it. Anthropic, OpenAI, and Qwen all encourage it. At the time of writing, over 60,000 public GitHub repositories already include one.
The premise is intuitive: give the coding agent a map of your repo: tooling, structure, style guides, and it will work more efficiently. Makes sense, right?
A new paper from ETH Zurich and LogicStar.ai — “Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?” is the first to rigorously test this assumption. And the results are not what most of us expected.

Table of Contents:
The Experiment: Two Benchmarks, Three Conditions
The Results: More Context, Worse Results
Agents Follow Instructions. That's the Problem
The “Aha” Experiment: What Happens When You Remove All Documentation?
Do Stronger Models Save You?
What does this mean for Developers & Should You Still Write AGENTS.md?
1. The Experiment: Two Benchmarks, Three Conditions
The authors evaluated four major coding agents: Claude Code (Sonnet-4.5), Codex (GPT-5.2 and GPT-5.1 Mini), and Qwen Code (Qwen3-30B) across two benchmarks and three conditions:
No context file: the agent works with only the repo and task description
LLM-generated context file: auto-generated using the agent vendor’s own recommended /init command
Human-written context file: written by the developers of the repository
To do this properly, they also introduced a new benchmark called AGENTBENCH: 138 real GitHub issues from 12 repositories that all contain developer-committed context files. This matters because existing benchmarks like SWE-Bench were built from popular repositories that predate the context file era.
2. The Results: More Context, Worse Results
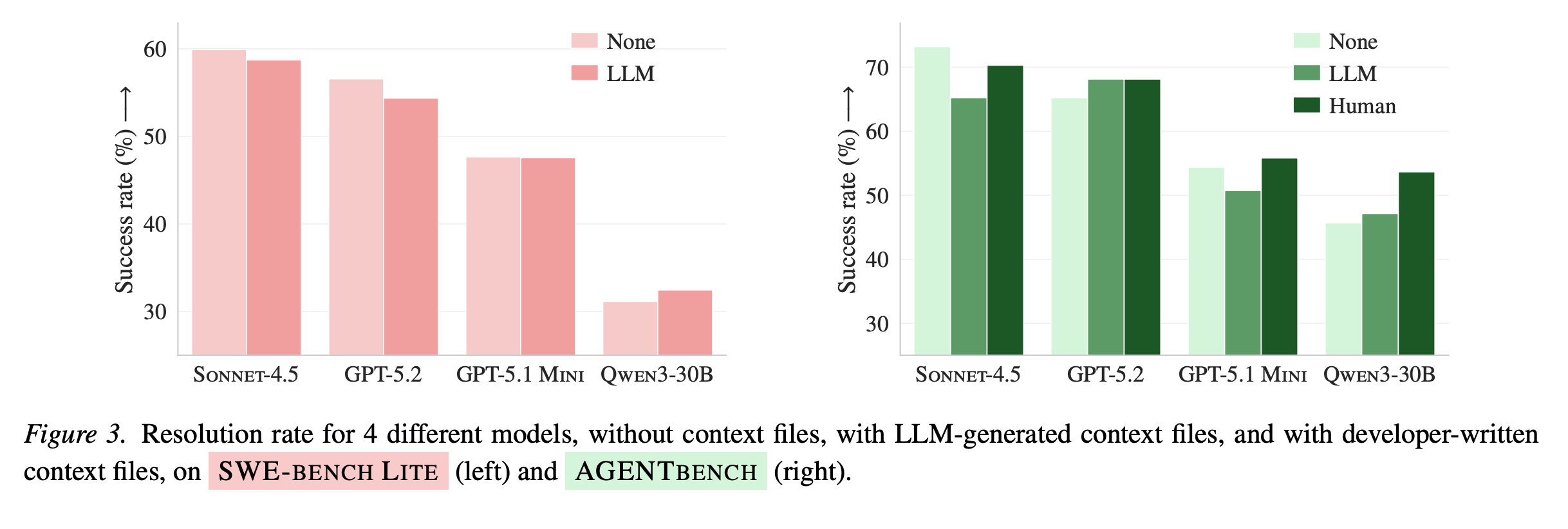
On both benchmarks, LLM-generated context files (red/pink) consistently perform below or equal to no context file (gray). Human-written files (dark green) perform slightly better, but the margin is small.
The numbers tell a clear outcome:
LLM-generated context files decreased task success by ~2-3% on average
Human-written context files improved it by ~4% — a marginal gain
Both increased inference cost by over 20% and made agents take more steps to complete tasks.
So agents are doing more work, costing more, and solving fewer tasks with only slight improvements in the case of human writer context files. That’s a problem.
3. Agents Follow Instructions. That’s the Problem
Here’s where it gets interesting. The issue isn’t that agents ignore context files. It’s the opposite.
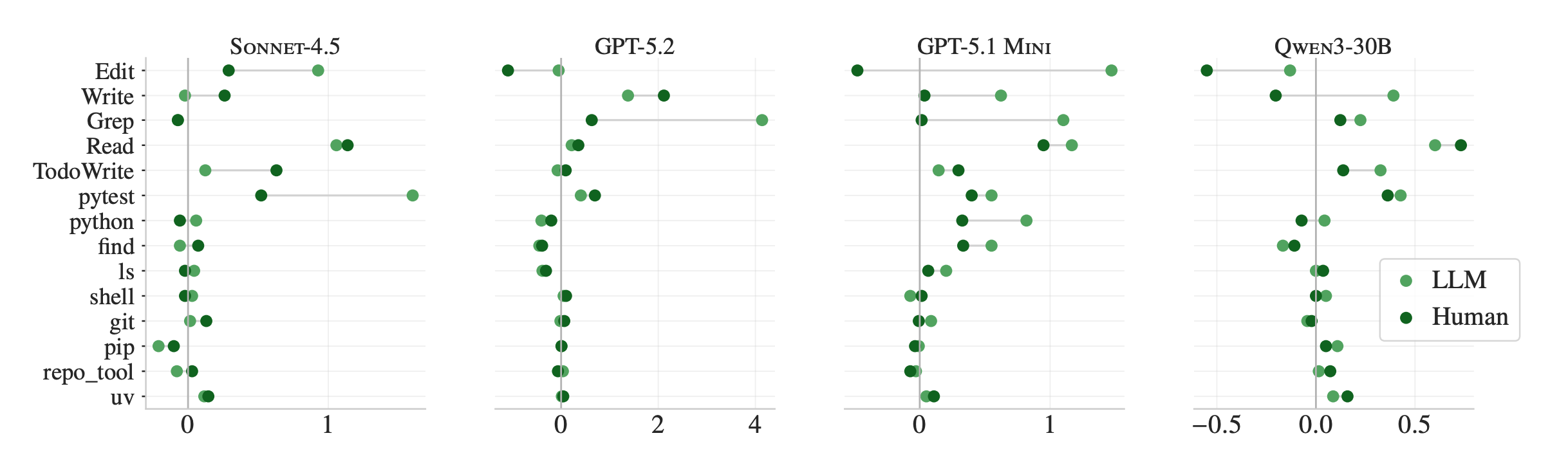
Across all agents, the presence of context files increases test runs, file reads, grep searches, and the use of repo-specific tooling. Agents follow the instructions, almost to a fault.
When a context file mentions UV, agents use it nearly exclusively. When it mentions repo-specific tools, those get called 2.5x more often. The instructions are followed. But following them triggers broader exploration, deeper testing, and more reasoning, without reliably improving the outcome.
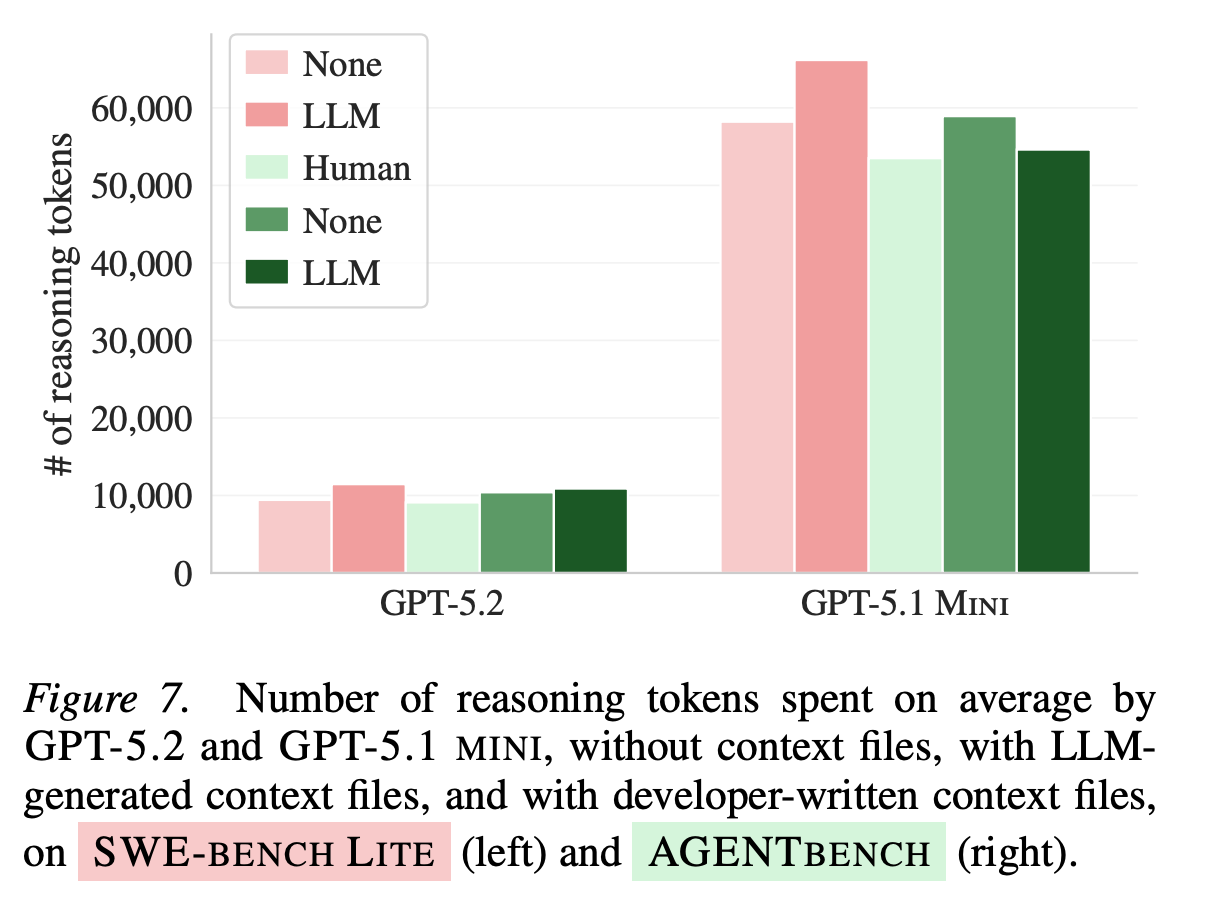
LLM-generated context files increased reasoning tokens by up to 22% for GPT-5.2. The agent is working harder — just not smarter.
As an AI engineer, this hit home. We often assume that more context equals better performance. But for autonomous agents, unnecessary requirements increase cognitive load. Agents, like humans, can be over-instructed.
4. The “Aha” Experiment: What Happens When You Remove All Documentation
The most revealing part of the paper is a simple ablation: what happens when you strip all documentation from the repository: READMEs, docs folders, markdown files, and leave only the context file?
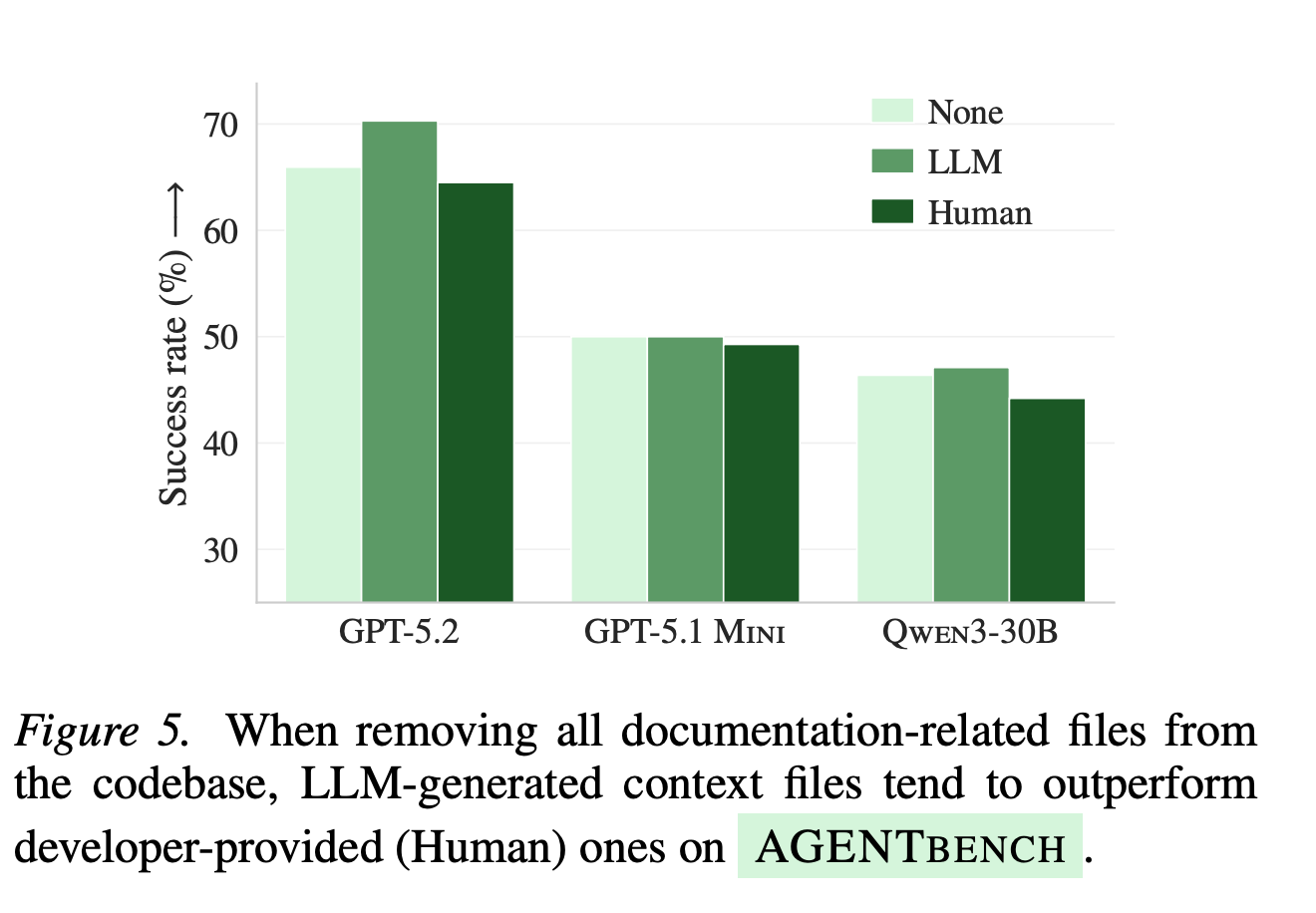
Without any other documentation, LLM-generated context files not only help — they outperform human-written ones.
This reframes everything. Context files aren’t bad by nature. They’re redundant in well-documented repositories. And redundancy, it turns out, is costly for agents. The anecdotal reports of context files helping? They likely came from less-documented, niche repositories where the context file was the only source of information the agent had.
5. Do Stronger Models Save You?
Two natural follow-up questions are answered in the paper:
Can stronger models generate better context files? No. GPT-5.2-generated context files improved performance on SWE-Bench but degraded it on AGENTBENCH. Better LLM ≠ better context file.
Does the prompt used to generate the file matter? Not consistently. Switching between Claude Code’s and Codex’s generation prompts produced no reliable improvement across agents.
6. What does this mean for Developers & Should You Still Write AGENTS.md?
The answer isn’t a blanket “don’t use context files.” It depends on the state of your repository’s documentation.
Well-documented repo? Skip the LLM-generated context file entirely. It will mostly restate what’s already in your READMEs and docs, and that redundancy is what drives up cost without improving outcomes. If you want a context file at all, write a short one manually — focused only on things the agent genuinely can’t infer on its own, like use uv, not pip, or run tests with pytest -x.
Zero documentation? Go ahead and generate one. The paper shows this is the scenario where LLM-generated context files actually earn their keep, performance improves, and they even outperform human-written ones. The agent has nothing else to work with, so the context file becomes genuinely useful rather than redundant.
Partially documented repo (the most common real-world case)? The paper doesn’t give a definitive answer here, but the logic is clear: generate it, then manually trim anything already covered elsewhere. What’s left, the non-obvious stuff, is what actually helps.
One thing holds across all cases: avoid directory overviews in the AGENT.md or CLAUDE.md. The paper tested this directly. Agents with detailed directory maps didn’t find relevant files faster. They just did more of everything — more reads, more searches, more reasoning — without a meaningful gain in accuracy. The overview feels helpful to write, but it doesn’t translate into better agent behavior.
The bottom line: context files are a compensation mechanism for missing documentation, not a performance booster on top of good documentation. Treat them accordingly.
This paper is a good reminder that in AI engineering, our intuitions often outrun the evidence. We adopted context files because they made sense in theory, everyone is using them, and because vendors told us to. But “it makes sense” is not the same as “it works.”
The real challenge isn’t giving agents more context. It’s giving them the right context: minimal, specific, and non-redundant, at the right time.
That’s a much harder problem. And a much more interesting one to solve.
This blog is a personal passion project, and your support helps keep it alive. If you would like to contribute, there are a few great ways:
Subscribe. A paid subscription to my newsletter helps sustain my writing and gives you access to additional content.
Grab a copy of my book Bundle. Get my 7 hands-on books and roadmaps for only 40% of the price
Thanks for reading, and for helping support independent writing and research!
Are you looking to start a career in data science and AI, but do not know how? I offer data science mentoring sessions and long-term career mentoring:

I've had the same problems described here. I added an AGENTS.md to one of my projects and Claude Code started running way more tests than it needed to. I thought I was helping by being thorough with instructions, but the redundancy with my existing README was making it do extra work. The ablation experiment where they strip all docs and then the context file helps, that proves the added documentation is just a gap-filler, not a performance booster.
Thanks for sharing this insight!
The bit about directory overviews not helping agents find files faster lines up with what I've seen. Agents are already decent at navigating codebases on their own; it's the unwritten team conventions they struggle with. My own AGENTS.md files have gotten shorter over time. Guardrails and conventions only, nothing else. Wrote up my approach to the cascading rules system here: https://reading.sh/the-definitive-guide-to-codex-cli-from-first-install-to-production-workflows-a9f1e7c887ab