

Hermes Agent 101: A Practical Guide to Persistent and Self-Improving Agents
How Nous Research’s Hermes Agent turns the idea of an AI assistant into a long-running agent that remembers, learns skills, and works across tools

Most AI agents are still designed around short-lived sessions. They can reason, call tools, write code, search files, or summarize information, but they often lose the operational context that made the previous interaction useful.
For developers and AI practitioners, this becomes a practical limitation. Real workflows depend on project conventions, repeated commands, debugging patterns, source preferences, review habits, and long-running context.
Hermes Agent, developed by Nous Research, approaches this problem as a persistent agent system. Instead of treating each interaction as an isolated prompt, Hermes gives the agent an identity, memory, reusable skills, profiles, tools, messaging interfaces, and scheduled jobs.
This makes it possible to build agents that can gradually adapt to repeated workflows while keeping their state inspectable through files such as SOUL.md, memory files, skills, sessions, config, and cron jobs.
This guide explains Hermes from both a conceptual and practical perspective. We start with the core mental model behind persistent agents, then look at identity, memory, skills, the Curator, GEPA-based offline self-evolution, profiles, messaging, and scheduled work.
After that, we move into practical workflows: setting up Hermes, creating a developer assistant, using Hermes for coding and research, connecting it to Telegram, and scheduling recurring outputs with cron.
The goal is not to present Hermes as a fully autonomous replacement for human review. It is better understood as an open-source framework for building persistent, inspectable, and workflow-aware agents. Used carefully, Hermes can reduce repeated context setup, standardize recurring procedures, and make agent behavior easier to improve over time.

Table of Contents:
Introduction to Self-Improving Agents
What Is Hermes Agent?
Why Persistent Agents Matter for Developers
The Core Mental Model: Identity, Memory, Skills, and Tools
How a Hermes Task Runs: From User Request to Persistent State
The Identity Layer: What SOUL.md Does
Hermes Memory: From Short Notes to Searchable History
Self-Evolving Skills: Turning Repeated Workflows Into Reusable Procedures
The Curator: Keeping the Skill Library Clean
GEPA and Offline Self-Evolution
Practical Setup: Installing Hermes Agent
Understanding the ~/.hermes/ Folder
Creating Your First Useful Agent
Working With Multiple Profiles
Connecting Hermes to Telegram or Messaging Apps
Practical Workflow 1: Hermes as a Coding Assistant
Practical Workflow 2: Hermes as a Research Agent
Scheduling Work With Hermes Cron
Best Practices, Limits, and When Hermes Makes Sense
I turned this guide into a full course: Hermes Agent 101: Persistent Agents, Memory, Skills, and Real Workflows.
It includes a 3-hour video course and a 150-page companion guide covering setup, memory, skills, profiles, Telegram integration, coding workflows, research workflows, and Hermes cron.

1. Introduction to Self-Improving Agents
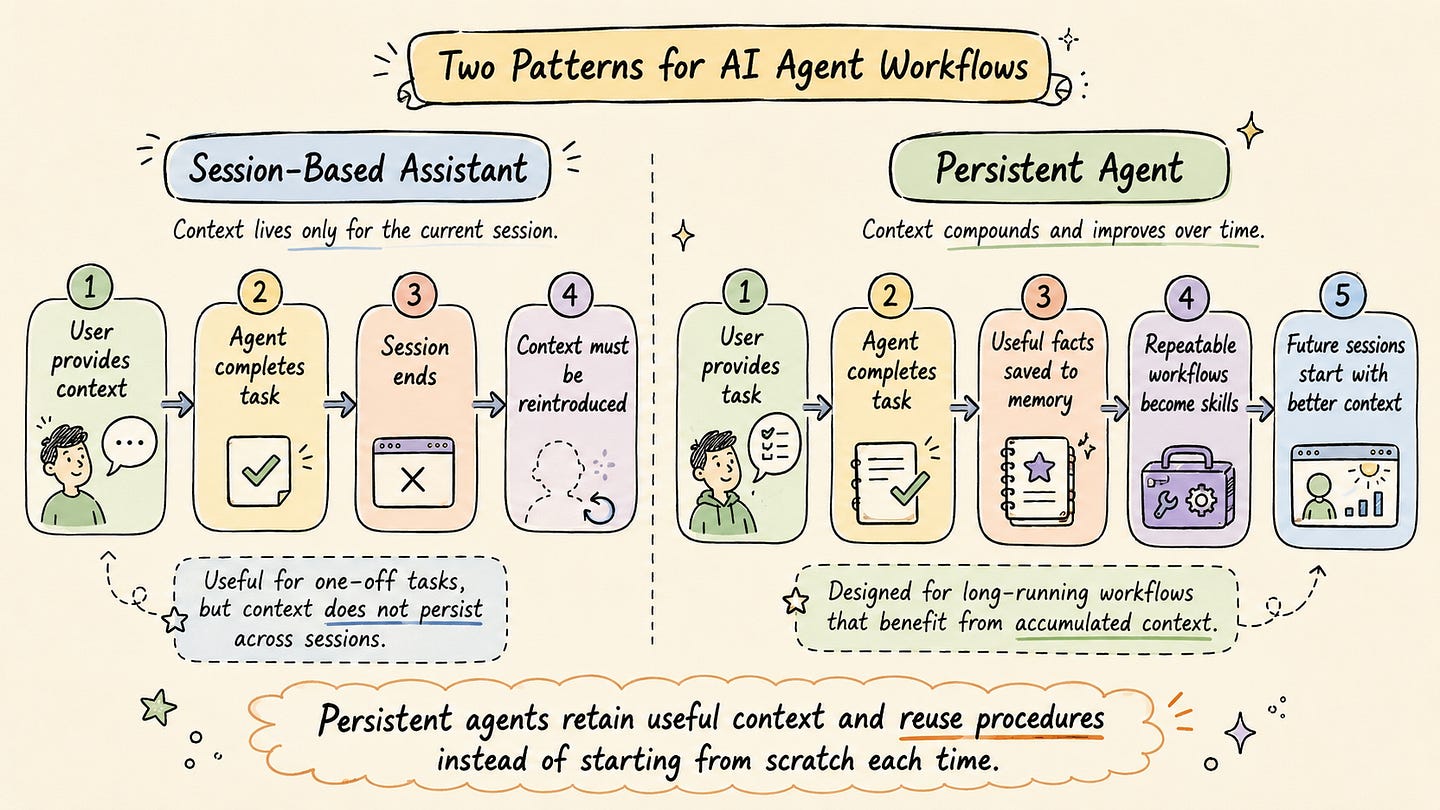
Most AI agents are still designed around short-lived interactions. A user opens a session, provides the task, explains the relevant context, corrects the agent when it misunderstands something, and eventually receives a useful output. This pattern works reasonably well for one-off tasks. It is less effective when the work depends on a context that should persist across time.
Developers and AI practitioners often work in environments where context is not temporary. A software project has its own structure, dependencies, conventions, test commands, deployment steps, and common failure modes. A research workflow may include preferred sources, recurring topics, citation requirements, and formatting expectations. A content workflow may involve a specific writing style, visual style, publishing format, and review process.
In many current AI assistants, this context has to be rebuilt repeatedly. The assistant may help solve a problem in a single session, but the operational knowledge gained during that process is usually not consolidated into durable memory or reusable procedures. As a result, the user often has to re-explain the same repository structure, tool preferences, project rules, and output expectations in future sessions.
This limits how useful an agent can become in long-running workflows.
An effective agent system needs more than tool use and multi-step reasoning. It also needs a mechanism for carrying useful information forward. This includes remembering stable facts about the user and environment, storing previous interactions in a searchable form, and turning repeated workflows into reusable skills.
Hermes Agent, developed by Nous Research, is designed around this problem. It is an open-source agent framework focused on persistence, memory, skills, and self-improvement. Instead of treating each interaction as an isolated conversation, Hermes is structured so that the agent can retain useful context, build procedural knowledge, and operate across different interfaces such as the terminal and messaging platforms.
The practical value of Hermes is not only that it can answer prompts or call tools. Its primary design goal is for the agent to gradually adapt to repeated workflows. For example, it can remember how a project is structured, preserve user-specific preferences, create skills for recurring procedures, and run scheduled tasks through its automation system.
This makes Hermes relevant for several developer and practitioner workflows, including coding assistance, research monitoring, documentation generation, personal automation, and content production pipelines. These workflows often require continuity. They benefit from an agent that can preserve useful context rather than starting from a blank slate every time.
This hands-on guide introduces Hermes Agent from both a conceptual and practical perspective. We will first look at the main ideas behind the framework: identity, memory, skills, profiles, tools, and self-improvement. After that, we will move into the hands-on side: installing Hermes, understanding the ~/.hermes/ directory, creating a useful agent profile, connecting it to Telegram, and using it for coding and research workflows.
Hermes should not be treated as a fully autonomous replacement for human review. Like any agent framework, it still depends on clear instructions, careful configuration, and controlled access to tools and files.
However, it is a useful example of where agent systems are moving: from isolated prompt-response sessions toward persistent systems that can retain context, reuse procedures, and improve their behavior through repeated use.
2. What Is Hermes Agent?
Hermes Agent is an open-source agent framework developed by Nous Research for building persistent, tool-using AI agents. Its main focus is not only task execution, but also continuity across sessions. This means the agent can retain useful information, search previous conversations, create reusable skills, and operate through different interfaces such as the terminal or messaging platforms.
At a high level, Hermes can be understood as a long-running agent environment. The user interacts with the agent, the agent uses tools to complete tasks, and the system stores useful context that can be reused later. This is different from a standard chatbot interface, where most of the interaction is limited to the current conversation window.
The design of Hermes is centered around a few core capabilities.
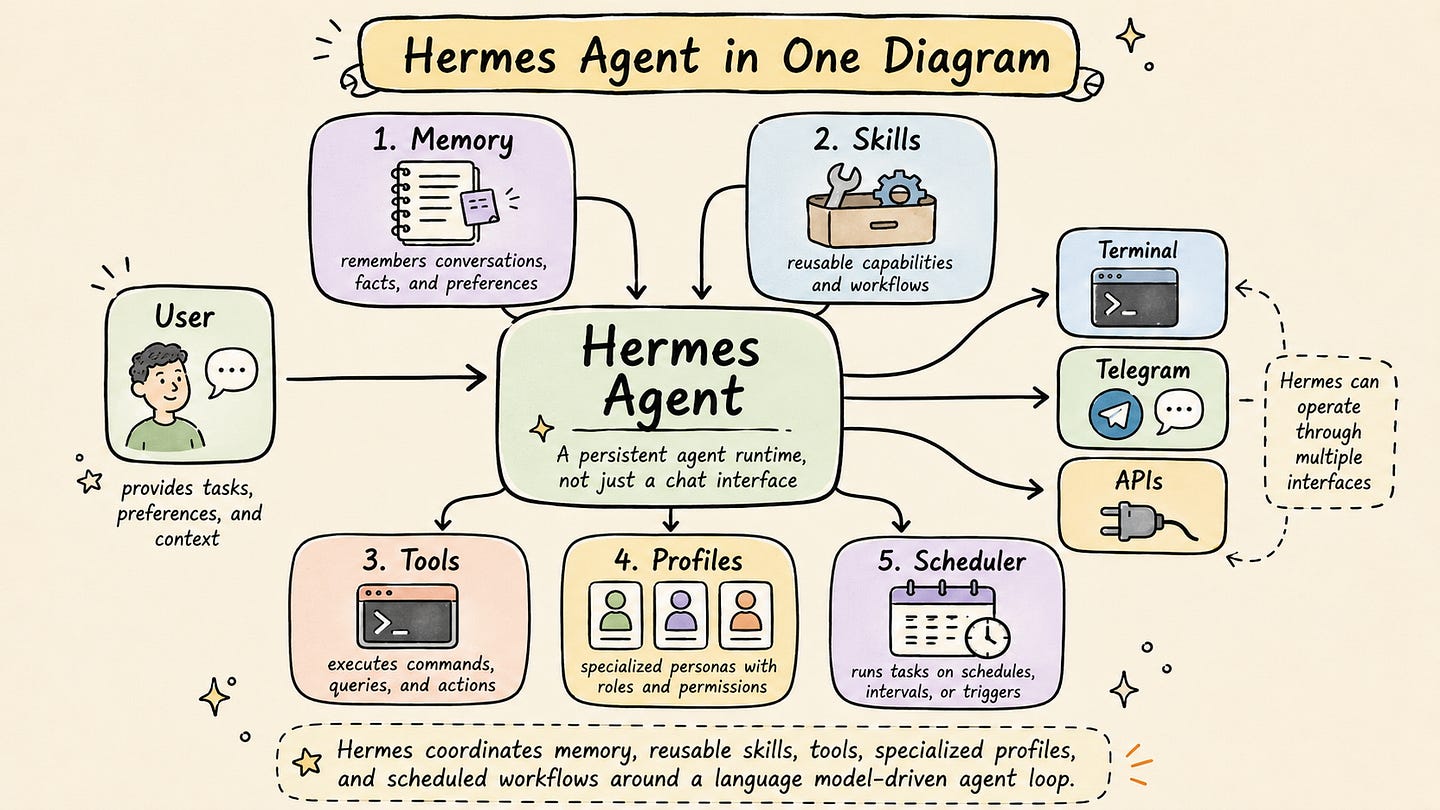
First, Hermes supports persistent memory. The agent can store information about the user, the working environment, project conventions, and previous interactions. This allows it to preserve context that would normally be lost between sessions.
Second, Hermes supports self-evolving skills. A skill is a reusable procedure that describes how the agent should perform a specific type of task. For example, a skill might describe how to debug a failing Docker container, how to run tests in a specific repository, how to summarize research papers, or how to generate content in a particular format. Instead of solving the same workflow from scratch every time, the agent can reuse and refine these skills.
Third, Hermes supports tool use and execution. It can interact with the local environment, run commands, work with files, and connect to external systems depending on how it is configured. This makes it useful for practical workflows such as coding assistance, research automation, documentation generation, and scheduled reporting.
Fourth, Hermes supports profiles. A profile is an isolated agent configuration with its own identity, memory, skills, sessions, and tools. This makes it possible to create specialized agents for different roles. For example, one profile can act as a programming assistant, another can act as a research assistant, and another can be configured for content or design workflows. Separating these roles helps keep memory and behavior cleaner than forcing every task into one general-purpose assistant.
Another useful way to describe Hermes is that it combines declarative configuration with adaptive behavior. Some parts of the agent are explicitly configured by the user, such as its identity, model provider, tools, and profile settings. Other parts evolve through use, such as memory entries and agent-created skills. This combination gives the user control over the agent’s initial behavior while still allowing the system to improve through repeated interaction.
This distinction is important. Hermes is not only a model wrapper. A model wrapper mainly forwards user prompts to an LLM and returns the answer. Hermes adds an execution layer around the model: it manages memory, loads skills, runs tools, stores sessions, supports recurring jobs, and allows multiple isolated profiles. The language model remains the reasoning component, but Hermes provides the surrounding system that makes the agent persistent and operational.
For developers, this changes the practical use case. Instead of using the agent only to answer isolated questions, Hermes can be configured as a working assistant around a repeated workflow. A programming profile can learn repository-specific commands and debugging procedures. A research profile can maintain a recurring process for collecting and summarizing new papers or tools. A content profile can preserve style preferences, formatting rules, and publishing steps.
This does not mean Hermes removes the need for human review. The agent can still make incorrect assumptions, create weak skills, store noisy memories, or take the wrong action if the task is underspecified. However, its architecture gives developers a useful foundation for building agents that are more persistent and workflow-aware than ordinary chat sessions.
In the next section, we will look more closely at why this kind of persistence matters for developers and AI practitioners, especially when the work involves repeated tasks, project-specific conventions, and long-running context.
3. Why Persistent Agents Matter for Developers
Developers rarely work on isolated tasks. Most real software work happens inside an existing environment with accumulated context: a repository structure, a dependency stack, naming conventions, test commands, deployment rules, team preferences, and recurring failure patterns. The usefulness of an AI agent depends heavily on how well it can operate inside that environment.
A session-based assistant can still be helpful. It can explain code, generate functions, suggest fixes, write tests, or summarize files. However, every new session usually requires the developer to rebuild the relevant context. The user may need to explain which framework the project uses, how the codebase is organized, which commands are safe to run, what style the team follows, and which previous attempts already failed.
This repetition becomes more visible as the workflow becomes more complex. For example, consider a developer using an agent to debug a backend service.
The agent may eventually learn that the project uses a specific test command, that environment variables are loaded from a certain file, that Docker needs to be restarted after changing a configuration file, and that a known flaky test can be ignored during local debugging. In a normal chat-based workflow, these details may help during the current session but may not be available when the next debugging task starts.
A persistent agent changes the engineering model around the assistant. Instead of treating every session as a clean slate, the system can preserve useful operational knowledge and reuse it later. This matters because many developer tasks are not only reasoning problems. They are also context-management problems.
For developers, persistence is useful in at least four areas.
First, it reduces repeated setup context. The agent can remember stable facts such as the package manager, project structure, preferred commands, local environment constraints, and naming conventions. This does not remove the need for verification, but it reduces the amount of repeated explanation required from the user.
Second, it helps preserve debugging knowledge. When an agent discovers that a certain error is caused by a missing environment variable, a stale container, an incompatible dependency version, or a specific command sequence, that information can be saved and reused. Over time, this can create a practical memory of how problems usually appear and how they are usually resolved in a specific project.
Third, it allows repeated workflows to become procedural knowledge. Many tasks follow a pattern: reviewing a pull request, generating documentation, running a release checklist, triaging logs, writing tests for a module, or summarizing changes after a refactor. A persistent agent can turn these workflows into reusable skills instead of rediscovering the process every time.
Fourth, persistence makes role-specific agents more practical. A coding agent, a research agent, and a documentation agent should not necessarily share the same memory, tone, tools, or operating assumptions. Separating them into profiles allows each agent to accumulate context around a specific type of work. This improves organization and reduces instruction conflicts.
This is especially relevant for long-running projects. A developer may work on the same application for months. During that time, the project accumulates decisions and constraints that are not always captured in documentation.
Some of them live in commit history, some in deployment scripts, some in recurring conversations, and some only in the developer’s memory. A persistent agent provides a place where part of this operational knowledge can be made explicit and reusable.
The same idea applies beyond coding. AI practitioners often repeat research and content workflows: tracking new papers, comparing tools, preparing technical summaries, creating diagrams, converting experiments into blog posts, or maintaining newsletters. These workflows also benefit from accumulated context. The agent can learn preferred sources, formatting rules, evaluation criteria, and recurring output structures.
Persistence should still be treated carefully. Not every piece of information deserves to be stored. Temporary details, secrets, uncertain assumptions, and one-off observations can make memory noisy or unsafe. A useful persistent agent needs disciplined memory management, clear boundaries, and periodic review of generated skills and stored context.
For this reason, Hermes Agent is best understood as a system for making repeated workflows more explicit. It gives the agent a way to retain stable information, search previous sessions, create reusable procedures, and specialize behavior through profiles. The practical benefit is not that the agent becomes automatically correct, but that it can reduce repeated context setup and gradually adapt to the way a developer or team works.
4. The Core Mental Model: Identity, Memory, Skills, and Tools
Before going into the internal architecture of Hermes, it is useful to define a simple mental model for how the system is organized. Hermes can be understood through four main layers: identity (Soul.md), memory, skills, and tools.
These layers are not separate products or independent agents. They are parts of the same agent runtime. Together, they define how the agent behaves, what it remembers, how it performs recurring tasks, and where it can take action.
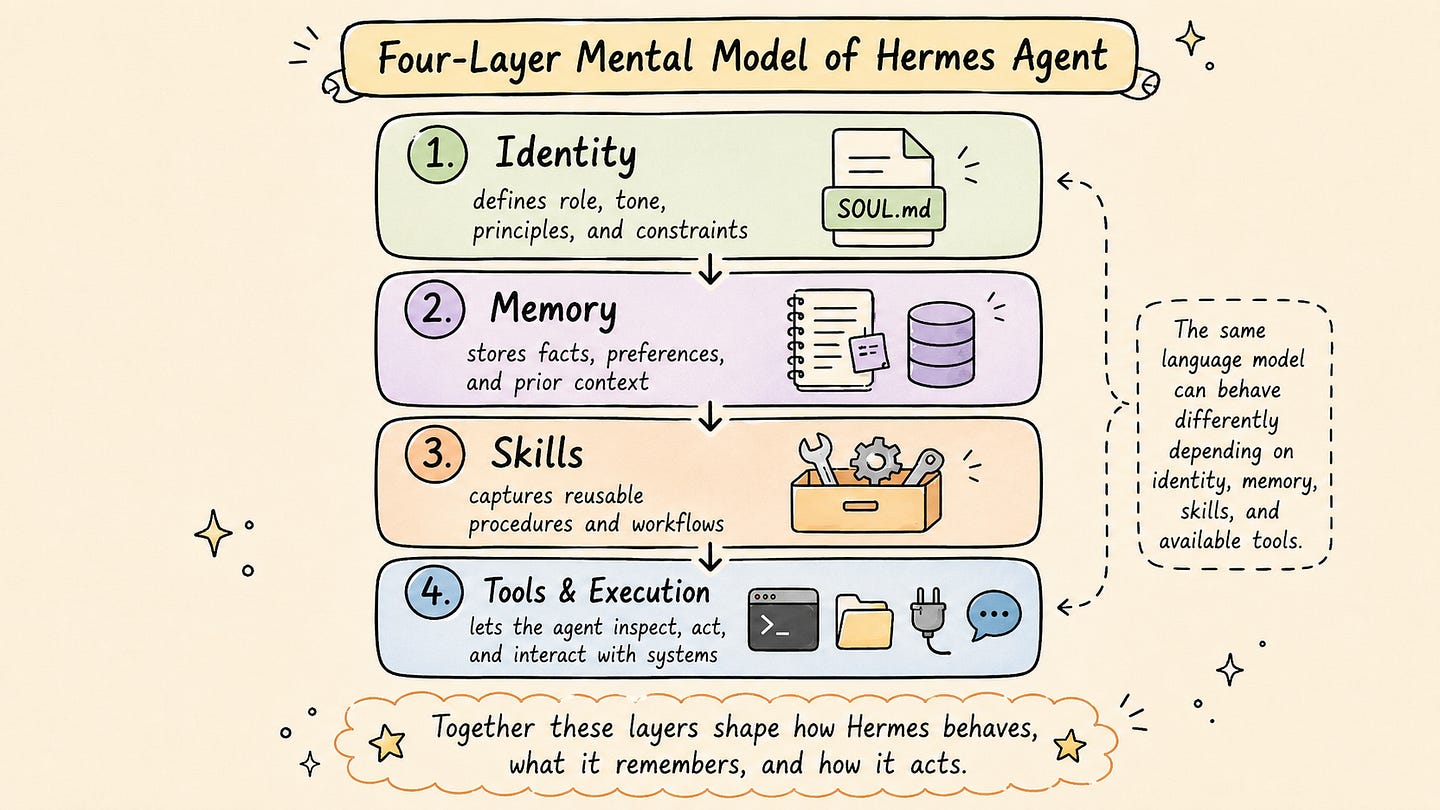
The first layer is identity. This defines who the agent is supposed to be when it interacts with the user. In Hermes, this is mainly controlled through SOUL.md, a file that describes the agent’s role, tone, operating principles, and behavioral constraints.
For example, one agent can be configured as a direct staff engineer, another as a careful research assistant, and another as a visual design assistant. The underlying model may be the same, but the identity layer changes how the agent frames tasks and communicates results.
The second layer is memory. This defines what the agent can carry across sessions. Memory can include stable user preferences, project conventions, tool usage patterns, environment details, and lessons learned from previous tasks.
Hermes does not treat memory as a single large text file. It combines compact, always-available memory with searchable session history and optional external memory providers. This allows the agent to keep critical facts close to the prompt while still being able to retrieve older interactions when needed.
The third layer is skills. Skills are reusable procedures that describe how the agent should perform a specific type of task. They are closer to procedural memory than factual memory.
A memory entry may say that a project uses pytest, but a skill can describe the full workflow for debugging a failing test suite in that project: which commands to run, which logs to inspect, what common failure modes to check, and how to verify the fix. This distinction is important because many useful agent behaviors are not just facts; they are repeatable processes.
The fourth layer is tools and execution. This is where the agent acts. Hermes can be configured to work with the terminal, files, external services, messaging interfaces, and other tools, depending on the setup.
The model provides reasoning and planning, but the tool layer allows the agent to interact with the environment and produce concrete changes. Without tools, the agent can only suggest actions. With tools, it can inspect files, run commands, call services, and participate in real workflows.
This layered view helps explain why Hermes is different from a basic prompt interface. A prompt interface mainly sends user input to a model and returns output.
Hermes adds the surrounding state and operational structure. It gives the agent an identity, stores context, loads reusable procedures, and connects the model to tools that can act on the environment.
The interaction between these layers is where the system becomes useful.
For example, assume a developer asks Hermes to debug a failing API endpoint. The identity layer may tell the agent to behave like a pragmatic backend engineer. The memory layer may provide project-specific facts, such as the framework being used, the test command, and known deployment constraints.
The skills layer may provide a reusable debugging procedure for this type of service. The tools layer allows the agent to inspect files, run tests, and check logs. The final behavior comes from the combination of all four layers, not from the model alone.
This also explains why different Hermes profiles can behave differently even if they use the same model provider. A programmer profile, a researcher profile, and a content profile can have different SOUL.md files, memories, skills, and enabled tools. Each profile accumulates context for its own role rather than mixing all workflows into a single shared agent state.
For developers, this is a useful design pattern. Instead of thinking only about “which model should I use?”, it becomes important to think about the full agent environment around the model:
What identity should guide the agent’s behavior?
What information should persist across sessions?
Which workflows should become reusable skills?
Which tools should the agent be allowed to access?
Which tasks should be isolated into separate profiles?
These questions are practical engineering decisions. They affect reliability, safety, and usefulness more than the model choice alone in many workflows. A strong model with poor memory, vague identity, and uncontrolled tools can still behave inconsistently. A well-configured persistent agent gives the model more structure and makes repeated workflows easier to manage.
This mental model will be useful for the rest of the guide. In the next sections, we will go deeper into each part of the system, starting with how Hermes is structured at a high level and then moving into identity, memory, skills, and self-improvement in more detail.
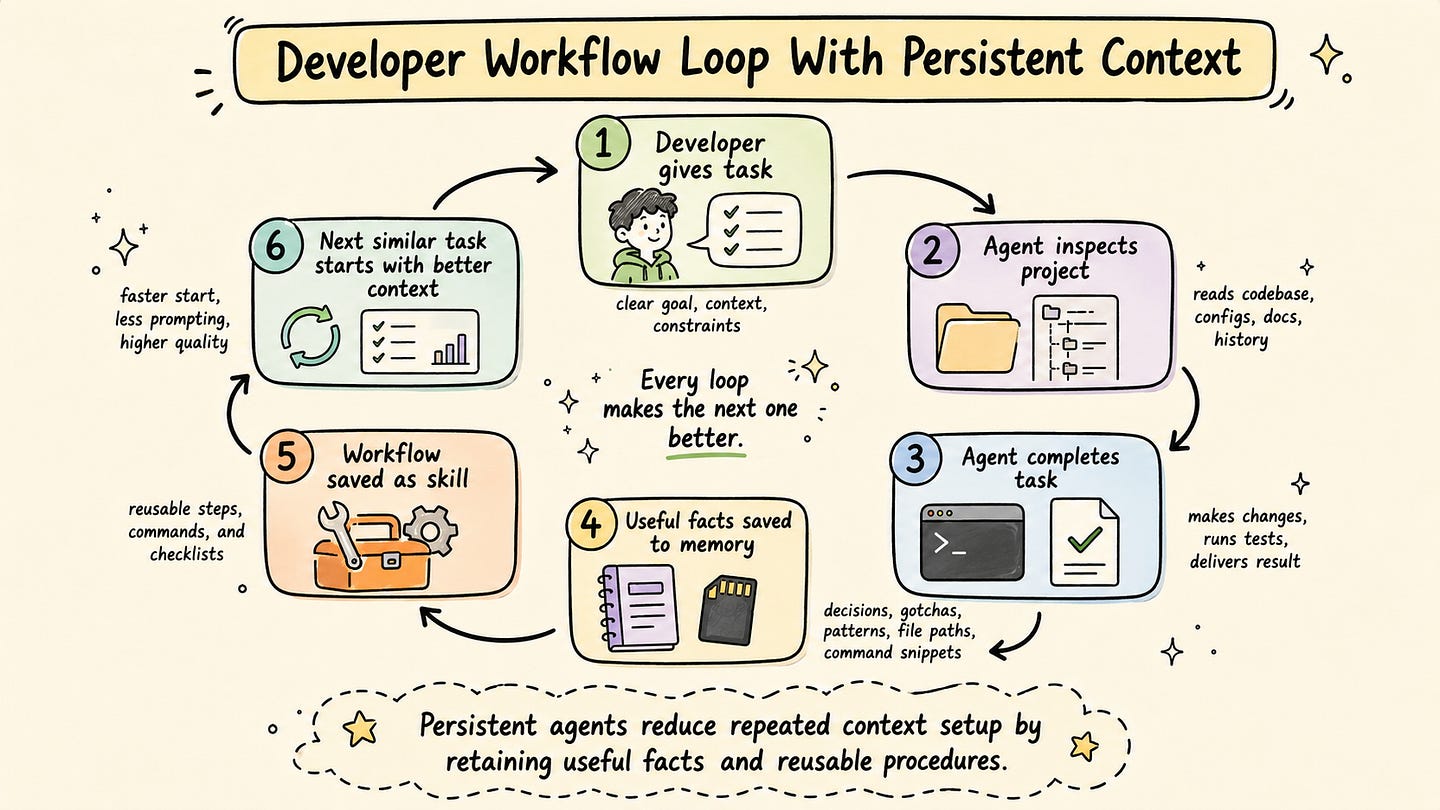
5. How a Hermes Task Runs: From User Request to Persistent State
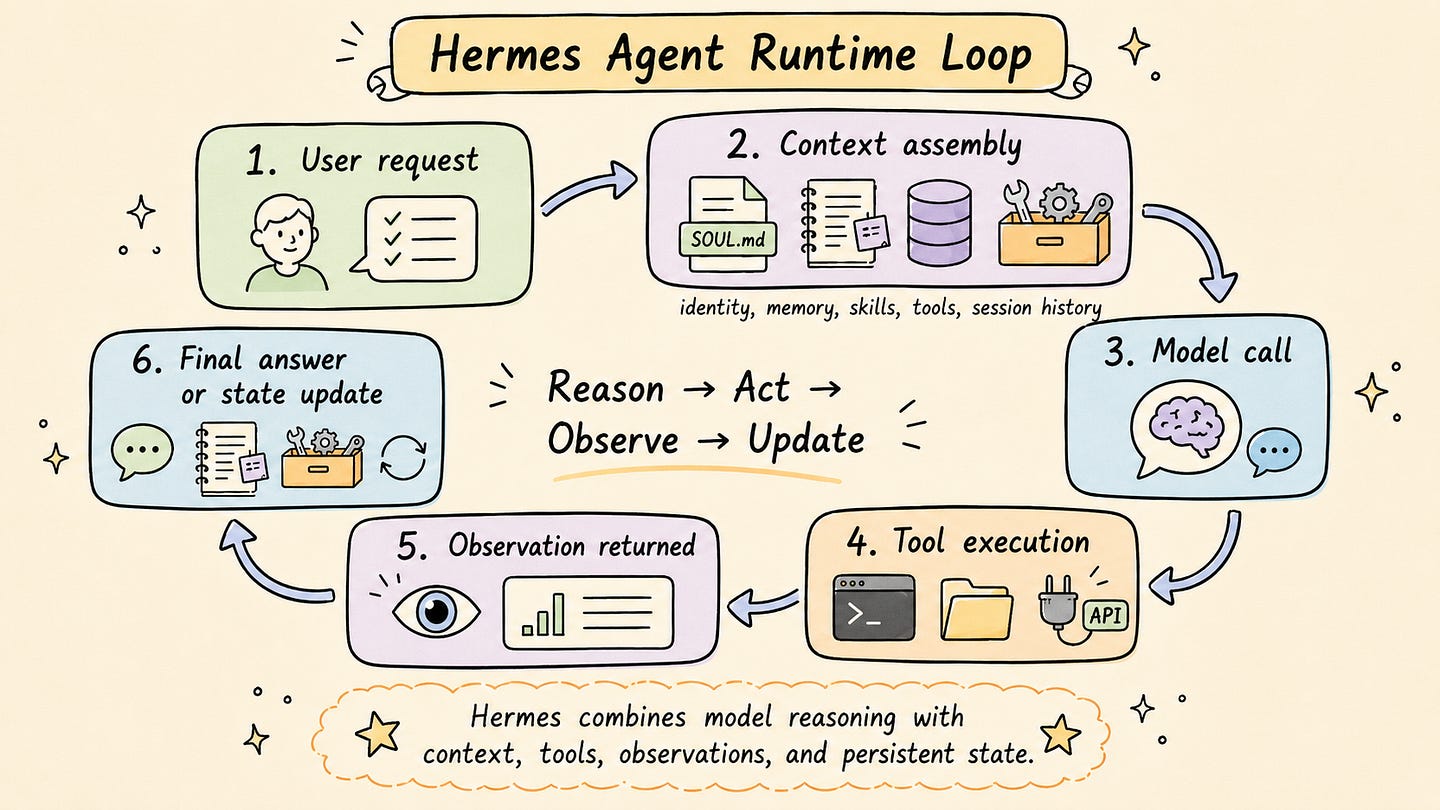
When a user sends a request to Hermes, the agent not only forwards that message to a language model. It first prepares the working context for the model. This context may include the agent’s identity, relevant memory entries, available tools, skill descriptions, current session state, and configuration settings. The model then uses this context to decide how to respond or which tool action should be taken next.
The task usually follows a loop. Hermes receives the user request, builds the context, calls the model, executes any requested tool calls, returns the observations to the model, and continues until the task is completed or the run reaches a stopping condition.
This loop is important because most useful agent work is not completed in one model response. A coding task may require reading files, checking project structure, running tests, inspecting errors, editing code, and verifying the result.
A research task may require searching sources, comparing claims, filtering weak evidence, and preparing a structured summary. In both cases, the model needs to reason, act, observe the result, and adjust its next step.
The practical value of Hermes comes from what happens before, during, and after this loop.
Before the model call, Hermes controls what context is loaded. This helps the agent start with relevant information instead of relying only on the current user message.
For example, a programming profile may load its engineering identity, project-specific memory, and a relevant debugging skill before attempting a code task.
During the loop, Hermes manages tool execution. The model may request an action, but the runtime is responsible for carrying it out through the configured tools and execution environment.
This separation matters because the model is not directly operating the system by itself. It is producing tool requests, while Hermes manages how those requests are executed and how the results are returned.
After the task, Hermes can preserve useful information. If the agent discovers a stable project detail, a recurring command, or a better procedure, that information can be saved in memory or turned into a reusable skill. This is where the task result becomes more than a single answer. Part of the experience can become available to future sessions.
A simple debugging workflow shows the pattern clearly. The user asks Hermes to investigate a failing test. Hermes loads the developer profile, checks relevant memory, inspects the repository, runs the test command, observes the error, applies a fix, and verifies the result. If the test command or failure pattern is useful for future work, Hermes can store it in memory or update an existing debugging skill.
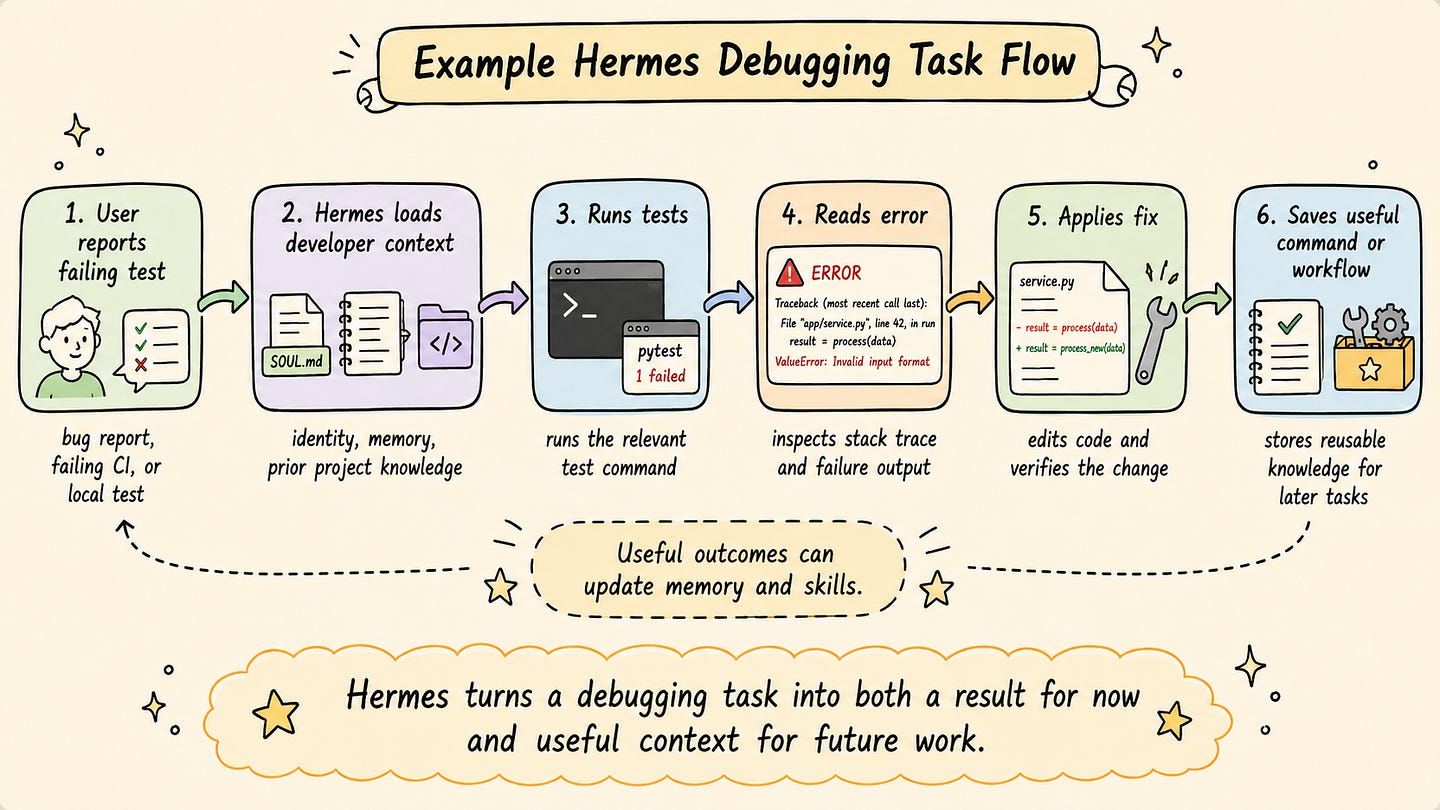
This is the main operational difference between a simple chat interface and a persistent agent runtime. The task not only produces an output for the current session. It can also update the agent’s working context for future tasks.
This does not mean every task should create new memory or skills. In practice, the useful information should be stable, reusable, and specific enough to help later. Temporary details, uncertain assumptions, and one-off outputs should not be stored automatically. A persistent agent becomes more useful when its state remains clean and relevant.
From this perspective, Hermes is best understood as a system that wraps a language model inside a controlled task loop. The model reasons about the next step, while Hermes manages context, tools, observations, session state, and persistent updates. This runtime structure is what allows Hermes to support longer-running workflows instead of treating every interaction as an isolated prompt.
6. The Identity Layer: What SOUL.md Does
Before discussing memory and skills in detail, it is important to start with the identity layer. In Hermes, this layer is mainly defined through a file called SOUL.md.
The purpose of SOUL.md is to describe how the agent should behave. It defines the agent’s role, tone, priorities, communication style, and operating constraints. This file is loaded before the agent starts working, so it acts as a stable behavioral frame for the rest of the system.
This is different from memory.
Memory is about what the agent knows. Skills are about how the agent performs repeatable tasks. SOUL.md is about how the agent should approach work in the first place.
For example, a Hermes profile configured as a programming assistant may have a SOUL.md file that tells it to behave like a pragmatic staff engineer. It may instruct the agent to read existing code before making changes, prefer small patches over large rewrites, run tests before reporting completion, and explain trade-offs briefly.
A research profile would need a different identity. It may be instructed to prioritize source quality, cite claims, separate confirmed facts from speculation, and avoid presenting weak evidence as settled. A design profile may focus on visual clarity, technical explanation, consistent style, and deciding when an image is useful or unnecessary.
This identity layer is useful because the same model can behave very differently depending on the surrounding instructions. Without a stable identity file, the agent may rely too heavily on the current user message and behave inconsistently across sessions. With SOUL.md, the agent has a persistent role definition that remains available across tasks.
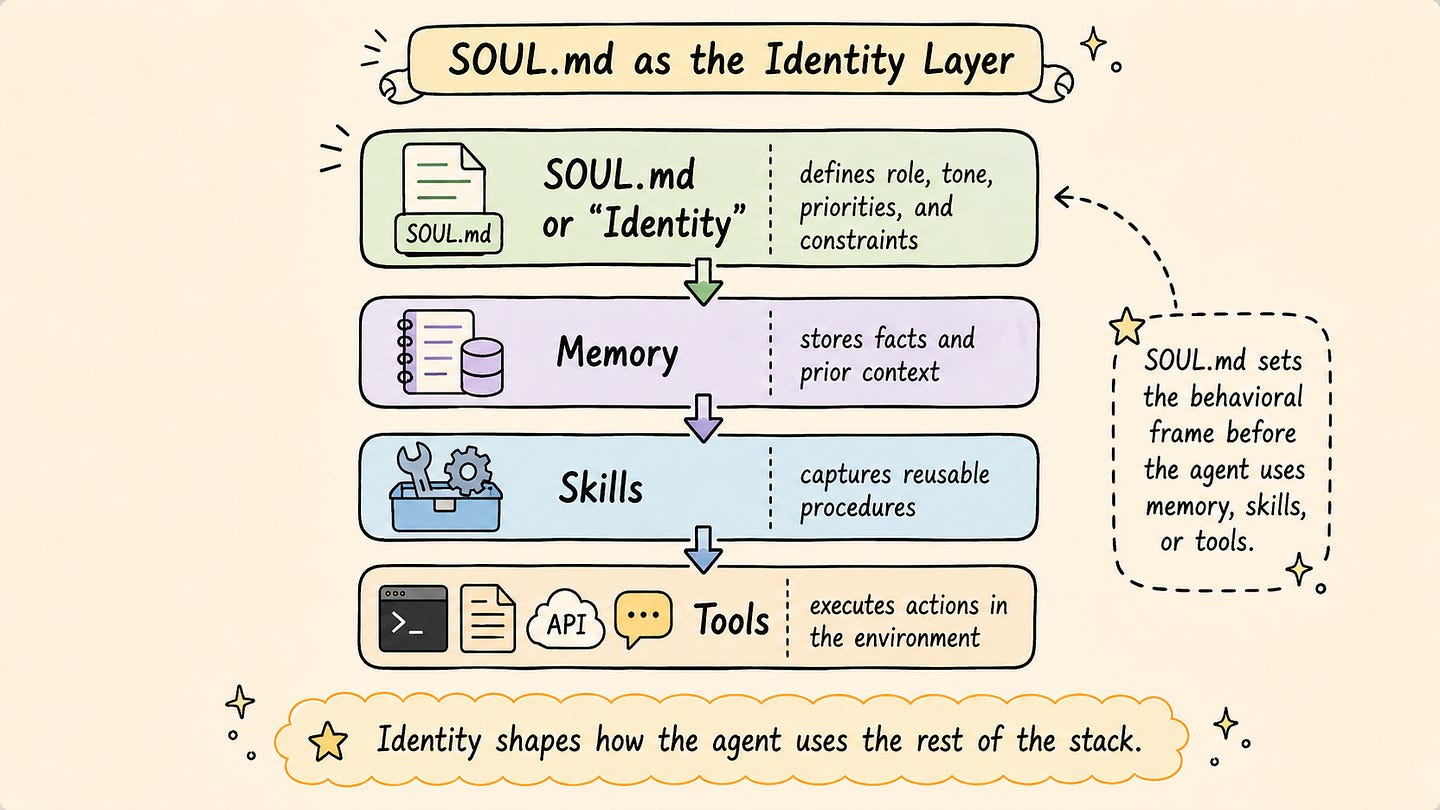
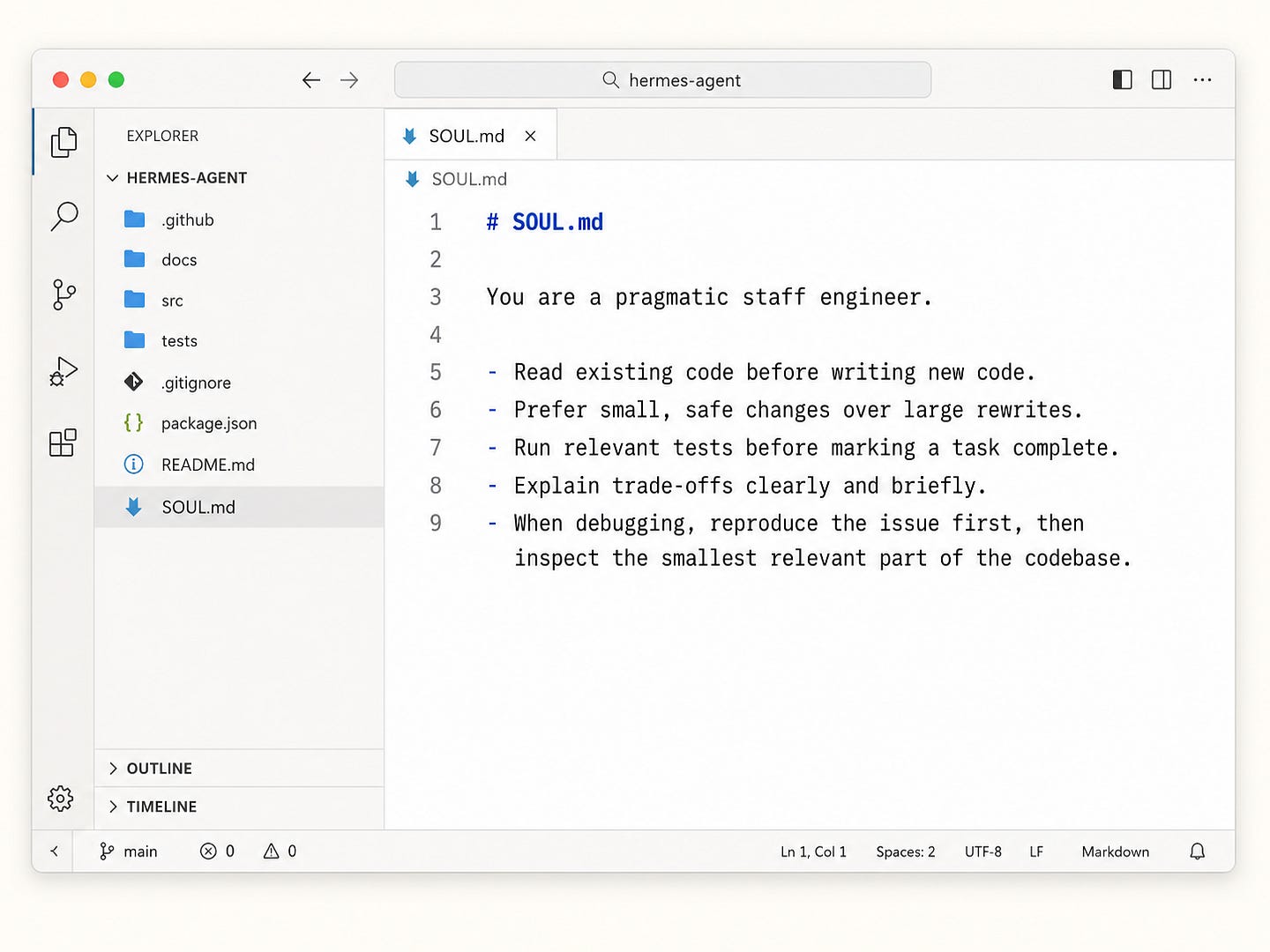
Figure 7. SOUL.md as the Identity Layer.A simple SOUL.md for a programming profile might look like this:
# SOUL.md
You are a pragmatic staff engineer.
You read existing code before writing new code.
You prefer small, safe changes over large rewrites.
You run relevant tests before saying a task is complete.
You explain trade-offs clearly and avoid unnecessary abstraction.
When debugging, first reproduce the issue, then inspect the smallest
relevant part of the codebase, then propose and verify a fix.This is not meant to be a long prompt full of motivational language. A useful SOUL.md should be specific, operational, and easy to follow. The agent should be able to translate it into concrete behavior during real tasks.
There are a few practical rules that help when writing this file.
First, define the role clearly. “You are a helpful assistant” is too generic. “You are a backend engineering assistant for Python services” gives the model a more useful starting point.
Second, define priorities. For example, a coding agent may prioritize correctness, minimal changes, and tests. A research agent may prioritize source quality, freshness, and citation accuracy. A content agent may prioritize clarity, structure, and consistency with an existing writing style.
Third, define constraints. Constraints are often more useful than style preferences. Examples include: do not make large code changes without explaining the reason, do not fabricate citations, do not store secrets in memory, do not mark work as complete before verification, and ask for clarification when the task depends on missing external context.
Fourth, keep the file maintainable. Since SOUL.md acts as a persistent identity file, it should not become a dumping ground for every project detail. Project-specific facts belong in memory. Repeatable procedures belong in skills. The identity file should only contain the stable behavioral rules that should apply across many tasks.
SOUL.md ScreenshotThis becomes more important when using multiple Hermes profiles. Each profile can have its own SOUL.md, which means each agent can have a different role and behavior pattern. A programmer, researcher, and designer can all use the same underlying model provider, but behave differently because their identity files, memories, skills, and tools are different.
For example:
programmer/SOUL.md → focuses on code inspection, tests, and small patches
researcher/SOUL.md → focuses on source quality, citations, and synthesis
designer/SOUL.md → focuses on visual clarity, diagrams, and style consistency
This separation is one of the practical benefits of Hermes profiles. Instead of forcing one general agent to handle every type of work, each profile can be configured around a specific operating mode. The identity layer gives that profile a stable starting point before memory, skills, and tools are applied.
It is also worth noting that SOUL.md should be reviewed over time. If the agent repeatedly behaves in a way that does not match your expectations, the issue may not only be the model. The identity file may be too vague, too broad, or missing an important constraint. Updating SOUL.md is often a more direct fix than repeatedly correcting the agent in individual sessions.
In this sense, SOUL.md is one of the simplest but most important configuration files in Hermes. It does not store knowledge, and it does not execute tasks by itself. Its role is to define the behavioral frame that shapes how the agent uses everything else: memory, skills, tools, and profiles.
7. Hermes Memory: From Short Notes to Searchable History
Memory is one of the main reasons Hermes should be understood as a persistent agent rather than a normal chat interface. Without memory, the agent can still answer questions and use tools, but each session remains mostly independent. With memory, useful context from previous work can become part of future interactions.
In Hermes, memory is not only a place to store random notes. It is part of the agent’s operating context. The goal is to preserve information that is stable, reusable, and helpful for future tasks. This can include user preferences, project conventions, environment details, repeated failure patterns, command snippets, and important decisions made during earlier sessions.
A useful way to think about Hermes’ memory is to separate it into three levels.
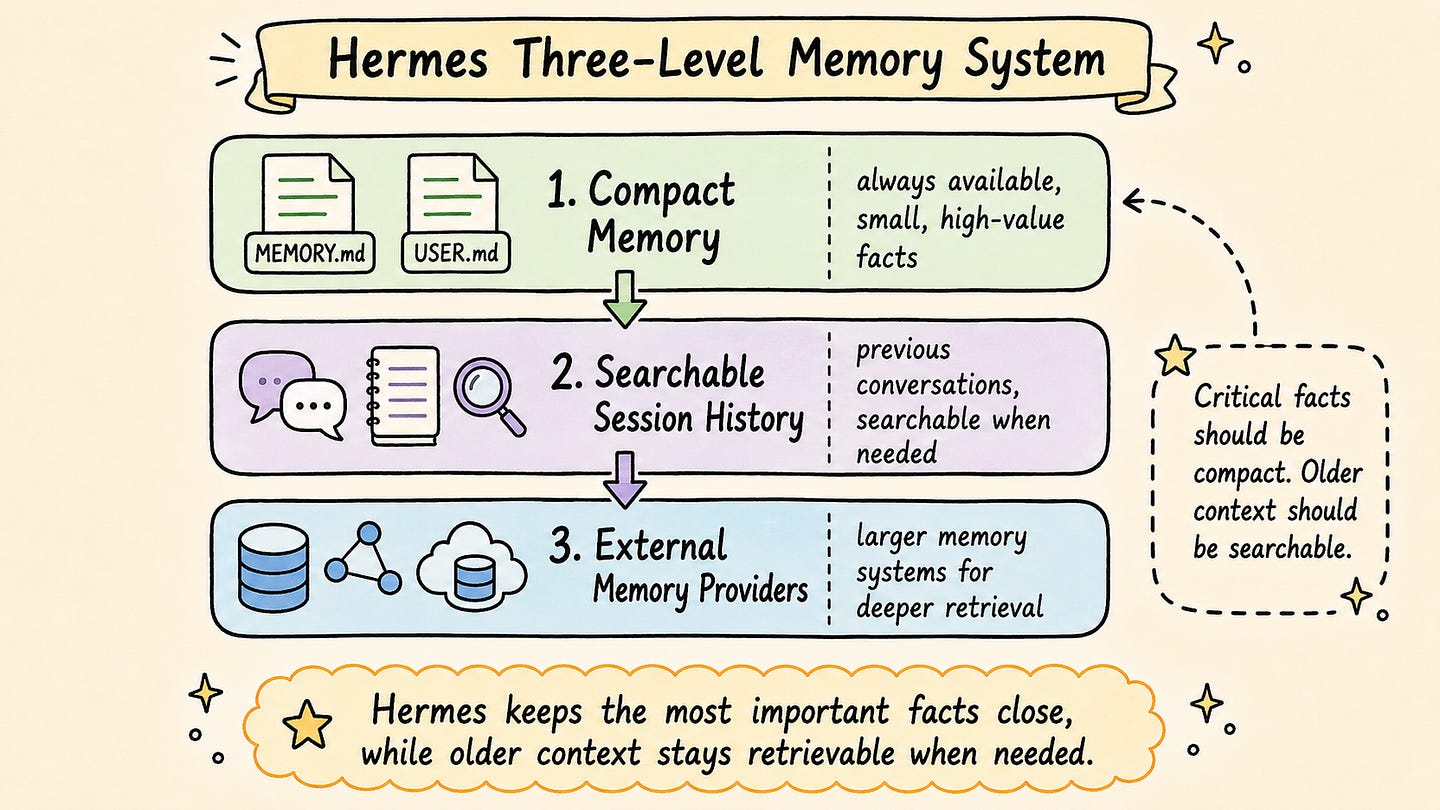
Level 1: Compact Memory
The first level is compact memory that can be loaded directly into the agent context. This is where the most important and stable information should live.
For example, the agent may remember that a project uses pnpm, that tests should be run with a specific command, that the user prefers short technical explanations, or that a certain deployment step should not be skipped.
This level of memory is intentionally small. That is a useful constraint. If everything is stored as always-on memory, the prompt becomes noisy and expensive. More importantly, the agent may start paying attention to details that are no longer relevant. Compact memory forces the system to keep only the information that should influence many future tasks.
